










フレア・リサーチの最新論文 論文は、AIとブロックチェーンを組み合わせることで、より安全で正確なAIを実現するという、人工知能(AI)への新たなアプローチを紹介している。
コンセンサス学習(CL)は、様々なアプリケーションにおける協調的AIを可能にし、より正確でロバストなAIモデルの開発を可能にする。CLは、ヘルスケアや金融など、データに敏感な分野におけるAI統合に特に適しており、意思決定プロセスを改善し、全体的な業務パフォーマンスと効率を向上させることで、最終消費者へのサービスコストの低減につながります。その結果、患者の治療結果が大幅に改善されたり、より正確な財務分析が可能になったり、不正検知が強化されるなど、さまざまなメリットがもたらされる。ブロックチェーンを通じて集中型の機械学習(ML)へのアクセスを可能にするAIとブロックチェーンの既存のほとんどの実装とは対照的に、CLはブロックチェーンを活用して分散型のAIモデルを作成する。
動機
近年、データや計算リソースが複数のデバイスに分散する分散環境が重視されるようになっている。この変化は、大規模な言語モデルやコンピュータビジョンモデルなど、処理に大量のデータを必要とする最新の基礎モデルの要件に促されている。このような分散型でありながら中央集権的な環境では、いくつかの重要な動機によって、分散化が基本的なニーズとして浮上してくる。
中央集権的な方法は、信頼できる単一の当事者に依存することで固有のリスクを伴うため、その使用は主に単一の企業環境に限定され、より広範な採用が制限される。さらに、このようなアーキテクチャは、潜在的な攻撃やシステム障害に対する脆弱性を増大させるだけでなく、データのプライバシーやセキュリティに関する懸念も引き起こす。逆に、分散型手法には明確な利点がある。それは、集中型アプローチではそのようなカスタマイズに必要な柔軟性が欠けていることが多いのに対し、分散型手法では、ユーザーが特定の要件や好みに合わせてパーソナライズされたローカルモデルを開発できることである。このような制約の中で、コンセンサス学習は、中央集権に関連する固有のリスクを軽減しながら、より高い回復力、プライバシー、適応性を提供する分散型MLソリューションとして浮上している。
コンセンサス学習の利点
コンセンサス・プロトコルは分散型台帳のセキュリティに不可欠であり、悪意のある攻撃からブロックチェーン・ネットワークを保護する。コンセンサスメカニズムをAIに活用することには多くの利点があるが、その中でも以下の点に注目したい:
- パフォーマンスの向上。CL手法は、アンサンブルに参加する各人のデータから恩恵を受け、バイアスを低減し、未知のデータに対するモデルの汎化能力を高める。CLはまた、中央集権的な手法と比較して、より正確なAIにつながる可能性がある。これは主に、ブロックチェーンがコラボレーションにインセンティブを与える能力を持っているためで、多様なモデルからの多様な洞察を組み合わせることに熟練することにつながる。これは、各参加者が隣接するモデルの予測を評価し、より精度を高めるためにそれらを統合する、複数のローカル集約によって達成される。これは、AIがブロックチェーンの統合から大きな利点を得ることができる最初の例の一つである。
- 安全性。隠された目的を導入しようとする悪意のあるアクターが存在しても、コンセンサス・メカニズムに組み込まれた安全機能により、CLモデルの完全性は損なわれない。これにより、AIシステムは、悪意のあるAIの特徴である、意図的な有害予測や意図しない不正確さを生成することがない。その結果、CLはAIコミュニティにおける主要な懸念に対処し、有害な目的への悪用からAIを保護する。協調学習プロセスの完全性を維持することで、CLはAIシステムにより大きな信頼と信用を与え、責任ある倫理的な展開への道を開く。
- データのプライバシー。CLでは、ネットワーク参加者の基礎データも個々のモデルも、いかなる時点でも共有されることはない。実際、データはローカルに保存されたままであるため、データの機密性を損なうような悪意のある攻撃がネットワーク上で行われることはない。プライバシーの保護は、コラボレーションを促進するだけでなく、競争力も維持する。この点で、CLは、特にヘルスケアのような機密データや商業データについて、AIによるデータ収益化を可能にし、集中型環境で遭遇した以前の課題を克服する。
- 完全な分散化。データと計算リソースは参加者のネットワークに分散され、単一の中央サーバーに依存することなく通信する。分散化の必要性は、膨大なリソースの需要とMLモデルの複雑化により、現代のMLアプリケーションにおいて顕著に表れている。分散化されたMLは、データのプライバシーを守り、セキュリティを確保するためのより適切なソリューションとして浮上している。
- 効率。学習プロセスはレイテンシーが低く、他の最先端の分散型ML手法と比較して、計算時間、エネルギー、リソースが非常に少なくて済む。このためCLは、迅速な意思決定と効率的なリソース利用が最優先されるリアルタイムアプリケーションに特に適している。
仕組み
コンセンサス学習は、参加者が合意に達するまで(モデルの)出力を共有するコミュニケーション・フェーズを通じて、アンサンブル手法を強化する。コンセンサス学習は2段階のプロセスで、以下のように実施できる:
- 個人学習段階。各ネットワーク参加者は、自分のプライベートデータや他の一般公開されているデータに基づいて、自分自身のモデルを開発する。これは、ゼロからモデルを構築するものから、事前に訓練された大規模なモデルを使用し、ニーズに合わせて微調整するものまで、さまざまです。重要なのは、参加者がデータやモデルに関する機密情報を共有する必要はないということです。これはスマートコントラクトを通じて開示されたデータセットである場合もあれば、例えばProof-of-Stakeメカニズムを通じて参加者が新しいテストデータポイントを提案する場合もある。
- コミュニケーション・フェーズ。参加者は、コンセンサス/ゴシップ・プロトコルに従って、最初の予測をネットワーク内に送信する。これらの交換の間、参加者は他のネットワーク参加者の評価と自分の予測の信頼度を反映するために、自分の予測を継続的に更新する。さらに、参加者はネットワークの他の参加者から受け取った予測の品質を監視し、意思決定の改善に役立てることができる。このフェーズの最後に、参加者は、ネットワーク内で利用可能な情報を考慮して最適と考えられる意思決定について合意(「コンセンサス」)を得る。このフェーズは、新しいデータが入力された場合に繰り返される。
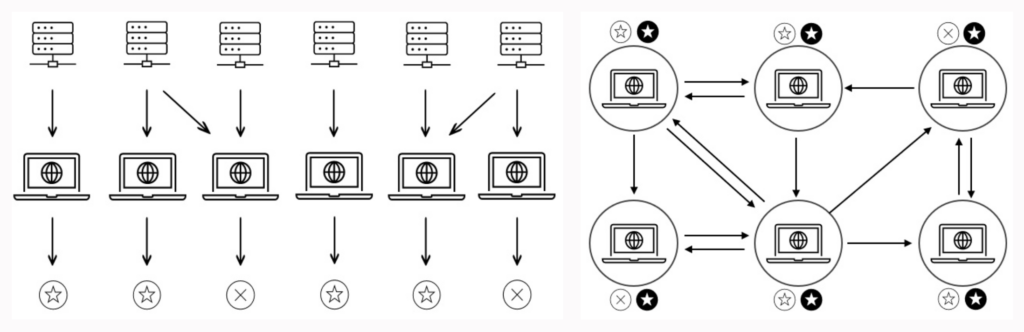
図のキャプション:CLが二値分類タスクでどのように機能するかの例。(a)最初の段階では、参加者は自分自身のデータと、場合によっては他の参加者が進んで共有する他のデータに基づいて、自分自身のモデルを開発する。この段階の最後に、各モデルはテストデータセットの任意の入力に対する初期予測(空洞の円で表される)を決定する。 (b)コミュニケーション・フェーズでは、参加者は初期予測を交換・更新し、最終的に1つの出力(塗りつぶされた円で表される)についてコンセンサスに達する。このフェーズは新しいデータ入力に対して繰り返される。
厳密に言えば、上述のアルゴリズムは教師ありMLのシナリオを指している。具体的には、訓練データセットが既にラベル付けされており、アルゴリズムが新しい、未見の、テストデータのラベルの予測を行う設定である。しかし、CLは、自己教師付きまたは教師なしML問題にも適応可能であり、そこでは、参加者は、部分的または完全にラベル付けされていないデータしか利用できない。これらの手法の目的は若干異なり、参加者は個人学習フェーズで異なるテクニックを用いる必要がある。それにもかかわらず、コミュニケーション・フェーズは上記の説明と同様の方法で進められる。
コンセンサス・ラーニングの特徴
CLの背後にある考え方は、機密情報や貴重な情報、知的財産を共有することなく、複数のソースからの知識(AIモデルの形)を効率的に組み合わせるというものだ。このアプローチは、機密情報を保護すると同時に、悪意のあるエンティティによってもたらされる潜在的なリスクに対する回復力を確保するように設計されている。CLは、複数のモデルを1つのモデルに統合するための強力な技術を提供し、大きな成功を収めたアンサンブル学習のパラダイムに基づいている。アンサンブル手法は、「群衆の知恵」の原則に依拠しており、群衆の集合的な知識を活用することで、どのメンバーの知識も凌駕する。
近年、AIサービスのブロックチェーン実装がいくつか登場し、AIを分散型ネットワークに統合する革新的なアプローチが紹介されている。例えば、Bittensorは、ゲーム理論的なメカニズムを通じて「マイナー」の予測に重み付けをすることで、ドメイン固有のサブネット内でのAIの推論(モデル出力)を容易にしている。FLock.ioは、モデルの更新を検証し、参加者に報酬を与えるためにブロックチェーンを活用し、中央集権的なアグリゲーターはあるものの、連合学習(異なるタイプの分散学習)のためのプラットフォームを提供している。もう一つの例はRitualで、Infernetプロトコルを通じてMLモデルのマーケットプレイスを実質的に運営している。
CLは、個々のモデルの予測が合意に達する目的で安全なゴシップ・プロトコルを通過するという、独自の集計方法によって自らを際立たせている。既存の実装ではブロックチェーンを通じて中央集権的なMLにアクセスできるのに対し、CLはブロックチェーンを活用して分散型のAIモデルを作成する。その焦点は、コラボレーションを通じてより正確で安全なAIを実現すると同時に、非公開の、しばしば機密性の高いデータを保有するエンティティが、データの機密性を確保しながらシステムに参加することを可能にすることにある。
要約すると
コンセンサス学習は、ブロックチェーンのような分散型台帳に直接機械学習を実装する画期的な機会を提示している。この取り組みにより、ブロックチェーン技術が既存のAIツールを根本的に改善することができる、斬新なアプローチの出現を目の当たりにすることになる。これは、ヘルスケアなど、従来はデータに敏感であった分野でのイノベーションと安全なコラボレーションのためのエキサイティングな可能性を開くものであり、コラボレーティブなML技術の採用のための舞台を整えるものである。さらに、悪意のある要因に直面したときのCL手法の回復力は、AIシステムに対する信頼を高め、その信頼性と完全性を強化する。
